科学研究
科研动态
由Google Deepmind促进
作者:365bet官网日期:2025/04/28 浏览:
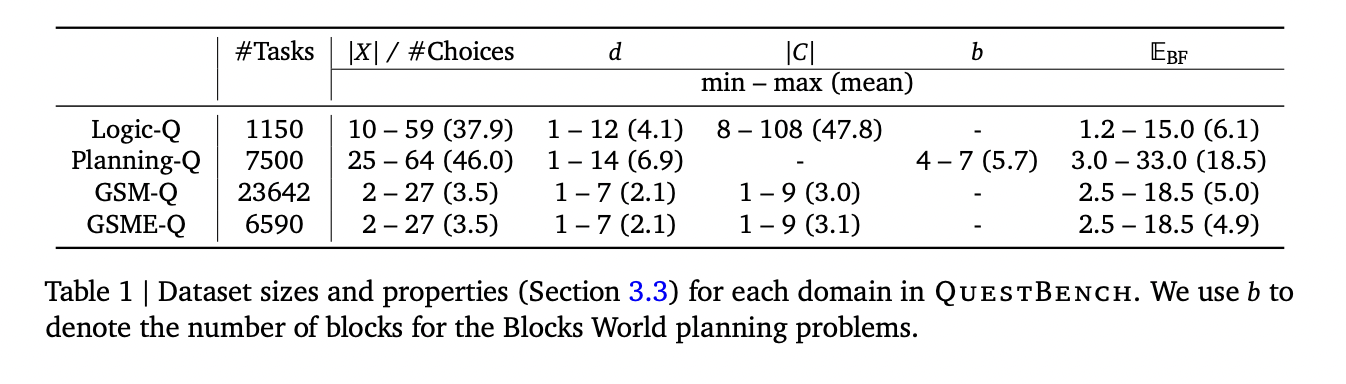 在新闻的4月26日的家中,技术媒体Marktechpost昨天(4月25日)发表了一篇博客文章,报道Google的DeepMind团队推出了新的QuestBench基准,以评估该模型通过问题(CSP)的轮廓来识别和获得有关推断的缺失信息的能力。对现实和信息获取要求的挑战大语言模型(LLM)已广泛关注识别任务,涵盖了数学,逻辑,计划和编码等领域。但是,现实世界的应用通常充满了不确定性。在提出数学问题时,用户通常会忽略重要的细节,而诸如机器人之类的自主系统也应在部分明显的Kapsaligiran上运行。这之间的这种矛盾是果断完成的信息设置和不完整的LLMS现实力量,以产生主动的信息采集功能。它引用博客文章来识别信息差距并生成有针对性的澄清问题,这是模型的关键,该模型为模糊情况提供了准确的解决方案。 QuestBench:一个新的框架,用于审查信息差距以应对信息获取挑战,研究人员介绍了QuestBench基准测试,该基准专门回顾了LLMS在理解任务中识别丢失信息的能力。该基准将把问题作为满意度问题(CSP)(CSP)征服,重点是“ 1-sufficial CSP”,也就是说,您只需要知道一个未知的可变valueto解决可变目标的问题即可。 Sakop Ng QuestBench Ang Tatlong Patlang:逻辑Pangangatuwiran(逻辑-Q),Pagpaplano(Pagpaplano-Q)在小学数学学院(GSM-Q/GSME-Q) ang lalim ng paghahanap在ang bilang ng mga hula na kinakailangan para sa pag-aasawa ng lakas,na tumpak na ibubunyag ang ang ang ang ang ang ang ang ang diskarte怀疑mOdel和瓶颈的性能。 QuestBench未来改进的模型性能和空间已经测试了顶级模型,包括GPT-4O,Claude 3.5十四行诗,Gemini 2.0 Flash思维实验,涵盖了零样本,思维链和四样本样本设置。该测试是在2024年6月至2025年3月之间进行的,并参与了288 GSM-Q和151 GSME-Q活动。结果表明,提示链提示通常会改善模型性能,而AOF Gemini 2.0 Flash思考实验最佳性能在计划活动中。开放资源模型具有逻辑推理的竞争力,但在复杂的数学问题上表现不佳。研究指出,当前模型在简单的代数问题上表现良好,但是随着问题的复杂性的增加,性能大大降低,以改善信息差距识别和澄清中信息的空间。
在新闻的4月26日的家中,技术媒体Marktechpost昨天(4月25日)发表了一篇博客文章,报道Google的DeepMind团队推出了新的QuestBench基准,以评估该模型通过问题(CSP)的轮廓来识别和获得有关推断的缺失信息的能力。对现实和信息获取要求的挑战大语言模型(LLM)已广泛关注识别任务,涵盖了数学,逻辑,计划和编码等领域。但是,现实世界的应用通常充满了不确定性。在提出数学问题时,用户通常会忽略重要的细节,而诸如机器人之类的自主系统也应在部分明显的Kapsaligiran上运行。这之间的这种矛盾是果断完成的信息设置和不完整的LLMS现实力量,以产生主动的信息采集功能。它引用博客文章来识别信息差距并生成有针对性的澄清问题,这是模型的关键,该模型为模糊情况提供了准确的解决方案。 QuestBench:一个新的框架,用于审查信息差距以应对信息获取挑战,研究人员介绍了QuestBench基准测试,该基准专门回顾了LLMS在理解任务中识别丢失信息的能力。该基准将把问题作为满意度问题(CSP)(CSP)征服,重点是“ 1-sufficial CSP”,也就是说,您只需要知道一个未知的可变valueto解决可变目标的问题即可。 Sakop Ng QuestBench Ang Tatlong Patlang:逻辑Pangangatuwiran(逻辑-Q),Pagpaplano(Pagpaplano-Q)在小学数学学院(GSM-Q/GSME-Q) ang lalim ng paghahanap在ang bilang ng mga hula na kinakailangan para sa pag-aasawa ng lakas,na tumpak na ibubunyag ang ang ang ang ang ang ang ang ang diskarte怀疑mOdel和瓶颈的性能。 QuestBench未来改进的模型性能和空间已经测试了顶级模型,包括GPT-4O,Claude 3.5十四行诗,Gemini 2.0 Flash思维实验,涵盖了零样本,思维链和四样本样本设置。该测试是在2024年6月至2025年3月之间进行的,并参与了288 GSM-Q和151 GSME-Q活动。结果表明,提示链提示通常会改善模型性能,而AOF Gemini 2.0 Flash思考实验最佳性能在计划活动中。开放资源模型具有逻辑推理的竞争力,但在复杂的数学问题上表现不佳。研究指出,当前模型在简单的代数问题上表现良好,但是随着问题的复杂性的增加,性能大大降低,以改善信息差距识别和澄清中信息的空间。 上一篇:我的强度风能光伏发电国的安装能力超过了热力
下一篇:没有了
下一篇:没有了
相关文章
- 2025-04-28分手后,该女子多次遇到她的男朋友,并
- 2025-04-27猫游戏的乐趣是什么?前10名顶级可玩猫
- 2025-04-26Redmi K80 5G手机16+1TB仅2135元
- 2025-04-26机械革命Wingsho 15 Pro Gaming笔记本原价849
- 2025-04-25三年内有150万个单位! JD.com和Vivo智能可